
Computers beating humans at chess is old news. But that’s precisely why it’s worth reviewing. Solved problems sometimes hold the best lessons. And the numerical chess rating system makes it particularly useful in quantifying some common assertions about the progress of technology.
Chess player’s competitive level is ranked using the ELO rating system. Players gain rating points by beating a competitor. And lose points when beaten. The scale is constructed so that “for each 400 rating points of advantage over the opponent, the chance of winning is magnified ten times in comparison to the opponent’s chance of winning.” The competition outcome is modeled as a logistics curve. The way the math works, when a player rated 1100 competes against a player rated 1000 (rating gap of 100), they’ll win 64% of the time. When a player rated 1400 player competes against a player rated 1000 (rating gap 400), they’ll win 92% of the time. What matters here is: a) the chess rating scale is exponential, and b) a 400 point gap means 10x better.
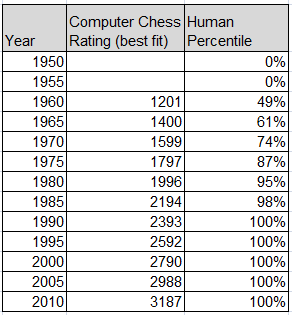
Luke Muehlhauser has a nice table on his web site showing the historical gain of computer chess ratings over time:

The linear fit works surprisingly well. We see a gain of roughly 400 points per decade, which as noted above means 10x better. This gives a doubling time of roughly 2 1/4 years. And don’t attribute this gain solely to Moore’s law. A modern chess engine running on the same hardware as an old one will win easily. Climbing the competitive slope required (and continues to require) constantly improving algorithms to get to the next level, not just faster hardware. There’s a saying in business that the winners are playing chess while everyone else is playing checkers. Here’s a case where that’s almost literally true. Playing checkers 10x faster is not enough. It never is.
Given the upper limit on human chess ability has hovered around the 2800 rating mark for a long time, and the grinding linear improvement (on an exponential scale) in computer chess, you might expect predictions about when a computer would beat the best human were consistently boring. Not at all! Tech enthusiasts constantly overstated the case, as this at times comical history shows. The first prediction that “within 10 years a computer would be world chess champion” dates to 1957. “Within 10 years” is claimed again in 1959. The first chess program that played chess credibly dates to 1962. So another “10 years” bet was made in 1968, and yet another in 1978. By the 1980’s it became clear where things were headed, though the topic continued to be hotly debated right up until 1997 when Deep Blue defeated reigning world champion Garry Kasparov.
Let’s now combine the computer chess rating improvements with percentile data on human players. Note this percentile is taken against chess players who compete regularly, not the general population. If we think about automation replacing human jobs, you can see why this works. We are comparing against people who’ve chosen chess in some sense as their vocation. If a computer is to replace a human in a particular job, we need to compare against people who’ve chosen that career. Not the general population, which has a much larger spread. Details on how this was done at bottom of the post. The result is the table below. To illustrate, in 1970 my fit line shows the best chess computer had an ELO rating of 1599, which turns out to be at the 74th percentile of regular chess players.
Below is the same data in chart form.
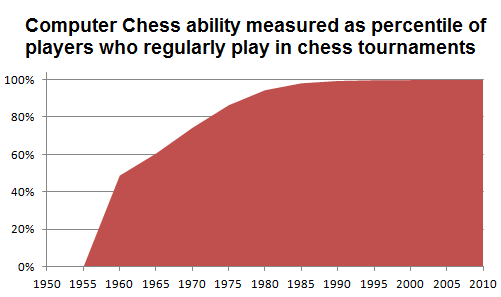
Prior to the late 1950’s computer chess wasn’t technologically possible, so you see a big jump in the early part of the curve. Then a burst of relatively fast progress as computers rapidly start passing most people in ability. Then at the tail end, getting better than the very best humans appears to take a long time, as the outer peak of human ability reaches very high. Let’s break this pattern out into four phases, and attempt to apply it to other technology trends. [Update: The framework below of course maps directly into Clayton Christensen’s three types of innovation. Phase 1 is empowering or disruptive innovation. Phase 2 is sustaining innovation. Phase 3 is efficiency innovation. Should’ve mentioned this when writing the original post.]
Phase 0: Failed Feasibility. In our Computer Chess timeline, this is pre-1955. This is the time before a technology is viable, and products don’t quite work but get lots of attention. Apple Newton. Early Virtual Reality.
Phase 1: Technical Feasibility. In our Chess timeline, this is the late 1950’s and early 1960’s. There’s a huge rush into the space. As Kevin Kelly has pointed out, when the time is right for an invention it tends to get re-invented by multiple people. Crazy ideas and expectations abound. We get excited claims that computers will be better than humans “within 10 years,” which eventually come true, but only decades after the original enthusiasts claimed they would. Hard to sort hype from the reality. Think Bitcoin or self driving cars now. Early World Wide Web in 1993-1994. First iPhone in 2007. Counterclaims come that this tech is just a toy and will turn into another Pets.com (which is sometimes the case). If you like technology, this is a pretty fun phase.
Phase 2: Grinding Exponential Improvement. In our Chess timeline, this is 1960-1990 where Chess programs went from a 1201 rating to a 2393 rating. This is 2393-1201 = 1192 rating points. Recall that 400 rating points is 10x better, so this is roughly 1000x better. Amazing! Going from barely able to play to better than all but the very best. This is where all the magic happens. Grinding away at incremental improvement. Yet people get bored during this phase. The winners in this era tend to be the ones determined in Phase 1, and the product improves people’s lives dramatically, but gets no respect. With very rough dates, think PCs from roughly 1984-2005, world wide web from 1995-2010, smart phones from 2007-2013 (just basic touch interaction of the operating system, not larger mobile ecosystems which still have huge changes coming). The media wants new product categories, not exponential improvements to the ones they already have. During this phase books like “Haunted Empire” get written about Apple not innovating anymore.
Phase 3: Plateaued slowed improvement. In our Chess timeline, that’s now. But even this phase is interesting. Chess computers currently continue to get better, and humans partnered with computers (Freestyle Chess) make stronger teams than computers alone. Eventually Chess will be solved like Checkers, and all games will end in a draw. Which means there exists an upper rating limit to Chess. After all, even Moore’s law will end it’s exponential run at some point.
What are some key takeaways? Exponential progress doesn’t look like the straight line in the top chart. It’s more like the chart below. From a human fixed vantage point, nothing happens for a long time. Doubling a millimeter doesn’t make make a flood much higher. By the time you get to a few centimeters you finally notice a change and see the water rising. Suddenly each double is huge and you’re underwater in an instant. You see amazing progress as your vantage point is reached and passed. Then the wave rides completely out of sight. In absolute terms we have a grinding exponential progress taking place the whole time. But the perception is utterly different. A second thing to notice is the exponential grind (phase 2 above) is where all the magic happens. Grinding iterative improvement is the secret sauce of the tech world. Finally, human ability has a shockingly massive range. We know this from sports when we say Messi is unwordly at soccer, or Michael Jordan was an inhumanly good basketball player. Magnus Carlsen has a 2881 chess rating! I played a bit in high school, and vaguely recall my rating was 1400 or so. Very mediocre 60th percentile. This means Carlsen is about 5000x better in a one on one competitive sense than I was at my very best. People talk about the best programmers being 10x better than the worst. Don’t buy it. Try something more like 100x or 1000x or more. The very best are simply playing a completely different game. It can be intimidating, but makes watching them great fun. Just don’t buy their hype though. When they claim their software will be better than humans in 10 years, reply that history shows 40 years is a far safer bet.

_____________________________________________
Appendix: Data calculation for percentile by year
- I pulled the computer chess chart from Luke Muehlhauser’s web site
- From there I did a linear fit to the year 1965 having a chess rating of 1400, and the year 2011 having a chess rating of 3227. Based on Luke Muehlhauser’s footnote on his chart. This gives chess computer rating by year.
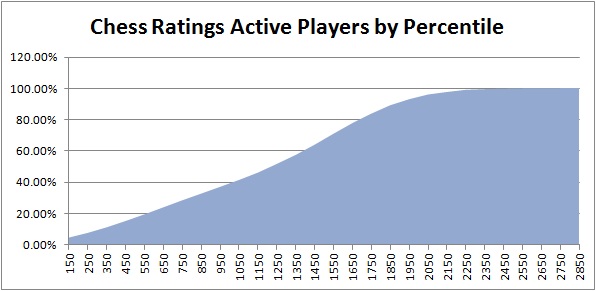
- I pulled human percentile data from the USCF site here. And used the non-scholastic (non-school kids) data. This means using regular chess players. For completeness, this data in chart form at bottom.
- I had to do a linear interpolation to get the final map from year to rating to percentile. For example, a rating of 2050 is 95.97% which maps to year 1986. And a 1950 rating is 92.94%, mapping to year 1978. From there I have to interpolate to get figure out that year 1980 was 94.59%.
- As a final note, obviously we can’t take comparing computer chess to other kinds of technology too literally. The analogy provides a feel for what we should expect, but the real world is always more complex than a board game.

Really nice work! I liked the 4 phases, though I’d argue there can be large field-specific steps/jumps.
It would be nice to see how this work ties into your predictions about the singularity and AI. On the one hand, it would seem AI is largely algorithm-bound, not hardware-bound. So I’m not sure AI progress is exponential. On the other hand, your work here seems to corroborate the singularity due to the exponential plot alone. If so, is AI in phase 2, wow some progress?
I understand Houdini 4 is now much higher rated than Deep Rybka. What is its rating?
all the chess engines, houdini rybka critter and stockfish are about the same, and this is only a guess, around 3700. Computers and top level grandmasters simply do not play because the grandmasters get nothing out of being beat by a computer. The last time a top level computer played high level grandmasters was the borislav ivanov cheating case where he was using the houdini 4 engine — even tho he never got caught we can tell just by looking at the moves the engine made. He beat grandmasters in ridiculous fashion mating them in the opening for example. But one grandmaster did manage to beat the cheater, that’s a 100 to 1 shot right there.
The 3700 rating is not indicated in the graph of your article.
From What I understand, Houdini 4 Pro with rating touching 3800 has almost 99.9 per cent chances of beating the current world champion who is around 2830, in almost all the 6 games, if they play. Something like Fischer beating Bent Larsen in a tennis like six zero result. Does it mean that now the “perfect” level is reached in game of chess?
I didn’t research where things stand today for chess engines as that wasn’t the main point of the post. But a quick search in wikipedia shows top chess engines today are about 3200. So that may be a good place to start.
http://en.wikipedia.org/wiki/Chess_engine#Ratings
Regarding “perfect” chess, beating humans 100% of the time doesn’t mean perfection. Just means much better than the best humans. Perfection is only reached when all games between the best computers result in a draw, and further improvements don’t change that result. At which point we’d say the game is “solved”. Like checkers already is. Since improvements continue to be made, chess computers aren’t yet perfect. This should also be evident in rate of ratings improvement slowing down before it stops.
Thanks for the correction.
Just a theoretical curiosity, for which you might have an answer.
If I put two computers, each with the best current software ( say Houdini 4 Pro) to play a matches continuously against each other and they play several tens of games, what would be the result?
Garry Kasparov (not Karparov)?
Whoops! Thanks for catching this. Fixed the post and changed it to Kasparov.