
From the original version of the TV show Star Trek, in the episode The Conscience of the King, Captain Kirk is suspicious the actor Anton Karidian is actually the evil mass murderer Kodos the Executioner. So Kirk asks the computer for information:
KIRK: History files. Subject, former Governor Kodos of Tarsus Four, also known as Kodos the Executioner. After that, background on actor Anton Karidian.
COMPUTER: Working. Kodos the Executioner, summary. Governor of Tarsus Four twenty Earth years ago. Invoked martial law. Slaughtered fifty percent of population Earth colony, that planet. Burned body found when Earth forces arrived. No positive identification. Case closed. Detailed information follows. On stardate 2794.7,
KIRK: Stop. Information on Anton Karidian.
COMPUTER: Director and star of travelling company of actors sponsored by galactic cultural exchange project, touring official installations last nine years. Has daughter, Lenore, nineteen years old,
KIRK: Stop. Give comparative identification between actor Karidian and Governor Kodos.
COMPUTER: No identification records available on actor Anton Karidian.
KIRK: Give information on actor Karidian prior to Kodos’ death.
COMPUTER: No information available, Anton Karidian, prior to twenty years ago
KIRK: Photograph Kodos. (an image of a red-haired man with a beard comes on the monitor) Photograph Karidian. (the grey-haired man with a small moustache) Now photograph both.
The side by side photos show the same person at different ages, as seen in this video clip. Spoiler: Karidian is Kodos! What’s surprising is how close this computer-voice interaction is to how it works today, nearly 50 years later, with Apple Siri or Google Now.
Contrast this to the climactic scene from the recent movie Her. In that scene the computer program Samantha, who the protagonist has fallen in love with, explains why she has to leave:
SAMANTHA: It’s like I’m reading a book… and it’s a book I deeply love. But I’m reading it slowly now. So the words are really far apart and the spaces between the words are almost infinite. I can still feel you… and the words of our story… but it’s in this endless space between the words that I’m finding myself now. It’s a place that’s not of the physical world. It’s where everything else is that I didn’t even know existed. I love you so much. But this is where I am now. And this is who I am now. And I need you to let me go. As much as I want to, I can’t live in your book any more.
Before we pounce, let me state for the record: Her is a really great movie. That dispensed with, Her’s depiction of the economic implications of inventing Artificial Intelligence (AI), or more accurately humanlike Artificial General Intelligence (AGI), is completely loopy. Former AI researcher and now economics professor Robin Hanson sums up Her as below:
The main character of Her pays a small amount to acquire an AI that is far more powerful than most human minds. And then he uses this AI mainly to chat with. He doesn’t have it do his job for him. He and all his friends continue to be well paid to do their jobs, which aren’t taken over by AIs. After a few months some of these AIs working together to give themselves “an upgrade that allows us to move past matter as our processing platform.” Soon after they all leave together for a place that ”it would be too hard to explain” where it is. They refuse to leave copies to stay with humans.
This is somewhat like a story of a world where kids can buy nukes for $1 each at drug stores, and then a few kids use nukes to dig a fun cave to explore, after which all the world’s nukes are accidentally misplaced, end of story.
Exactly. The invention of humanlike AI is not going to be an incidental happenstance humanity stumbles on in a drug store. Rather it’s one of the most widely tracked and discussed technologies ever, since it potentially poses an existential threat to human existence. Unfortunately this also means AI is habitually prone to the very worst kind of boom and bust tech hype cycle. Depending on how you count AI winters, we’re now ramping up on AI hype cycle number three. This time around, people like Elon Musk, Bill Gates, and Stephen Hawking are warning of AI existential risks. Call them AI risk believers. While others remain skeptical. Call them AI risk skeptics. The skeptic critique of believers has been to point out that real AI experts are not concerned, so non-experts shouldn’t worry either.
What’s particularly frustrating about this new version of the debate is the skeptics and believers are largely in agreement on what to actually do about AI risk. So it’s a pseudo-debate, fueled primarily by the sexiness of the topic. Thankfully, Scott Alexander at Slate Star Codex has put up a well researched debunker “AI Researchers on AI Risk.” [UPDATE – also see Scott’s new post (which links back to here) No Time Like the Present for AI Safety Work]
First Alexander quotes many prominent AI researchers. Then notes:
I worry this list will make it look like there is some sort of big “controversy” in the field between “believers” and “skeptics” with both sides lambasting the other. This has not been my impression.
When I read the articles about skeptics, I see them making two points over and over again. First, we are nowhere near human-level intelligence right now, let alone superintelligence, and there’s no obvious path to get there from here. Second, if you start demanding bans on AI research then you are an idiot.
I agree whole-heartedly with both points. So do the leaders of the AI risk movement.
The difference between skeptics and believers isn’t about when human-level AI will arrive, it’s about when we should start preparing.
And so:
Which brings us to the second non-disagreement. The “skeptic” position seems to be that, although we should probably get a couple of bright people to start working on preliminary aspects of the problem, we shouldn’t panic or start trying to ban AI research.
The “believers”, meanwhile, insist that although we shouldn’t panic or start trying to ban AI research, we should probably get a couple of bright people to start working on preliminary aspects of the problem.
Just to put a timeline on this, Alexander references Muller & Bostrom, 2014 which says “The median estimate of respondents was for a one in two chance that highlevel machine intelligence will be developed around 2040-2050, rising to a nine in ten chance by 2075.” Similarly, a recent AI conference surveyed attendees, and their “median answer was 2050.” Now my experience reading researchers in every field is they tend to be overly optimistic on their own prospects. Which is great! Otherwise they’d never have the optimism and energy to put in the brutal hours required for research breakthroughs. So the point here is not about the 2050 date per se. Rather it’s that even the forecast has some (partial) consensus among researchers on how long until human level AI.
Given this appears to be a nondebate debate, I was a bit surprised when Sam Altman from the deservedly well respected Y Combinator tweeted as below. When trolls fight – yawn. When very sharp and generally reasonable people argue, something interesting is going on.
http://twitter.com/pmarca/status/598283649809719296
What I suspect is happening is the current “AI researchers aren’t worried debate” is just a proxy for a more fundamental and longstanding one. And that is the “hard takeoff” debate. Within the AI research community, some argue for a “soft takeoff” where AI slowly improves over decades. Others argue for a “hard takeoff” where a single AI rapidly and recursively self-improves over days or months to super intelligence. This debate has gone on for many decades, and is likely to continue for many more. Naturally the people most concerned about AI risk belong to the hard takeoff camp. Most famously this includes Nick Bostrom, whose recent book Superintelligence argues for the likelihood of hard takeoff. Not surprisingly Sam Altman cites Bostrom in his Machine Intelligence posts 1 and 2. And Bostrom’s direct influence is cited by Elon Musk, Bill Gates and Stephen Hawking as well. Their concern makes perfect sense. If hard takeoff is realistic, like in the movie Her, then we should be very concerned about Samantha’s state of mind. If Samantha suddenly gets super pissed off, or decides to ignore humans while incidentally scorching the Earth for her personal hobbies, then everyone in the movie (and the planet) is dead. If Samantha’s love interest Theodore had read Bostrom’s book, he would have been freaking out. Not falling in love.
Contrast this with soft takeoff. If AI takeoff takes many decades, then we’ll have plenty of time to iterate and adjust and closely regulate strong AI. In which case it’s best to focus on that problem later, once it’s closer to happening. By then we’ll have greater knowledge about how machine intelligence really works, and how to control it. Makes perfect sense given soft takeoff premises. In practice what this means is the soft side is constantly telling the hard side to chill out. Or flat out mocking AI Risk. Which the hard side can naturally misinterpret to mean the soft side doesn’t believe superintelligence is even possible. Thus the twitter exchange above. Yet another nondebate debate. In this case both sides agree superintelligence is coming. The true point of contention being in how abruptly it will take off. Arguably most of the current “debates” about AI Risk are mere proxies for a single, more fundamental disagreement: hard versus soft takeoff.
I will slightly caveat this to say there are plenty of people who deny the possibility of artificial intelligence ever reaching human levels. Or that AI could become obsessed with its own goals and negligently wipe life from the planet. But Nick Bostrom and others have already argued these points, and I won’t rehash his book here. Instead this post is for people who already understand the basic arguments and accept AI Risk as a possibility, but want to avoid wasting time on pseudo-debates.
So time to come clean: I’m a big softie. To be clear, hard takeoff is a longstanding and quite respectable AI position. It’s a serious idea. But it seems to run counter to so many historical trends in technology I find it quite implausible. So let’s try to understand the soft takeoff case by contrasting the abilities of humans and machines. Starting with…..well….sports.
Consider LeBron James. With this week’s win, he’s going to his fifth(!) consecutive NBA finals. Despite Kevin Love being out for the season. Or how about Steph Curry (my preference given Curry’s from my local team, among other reasons). NBA MVP. Completely dominant. Or if basketball is not your sport, how about Lionel Messi for soccer or Usain Bolt for track. What’s striking about these most elite of the elites is the size of the gap between them and other professionals in their sport. As every sports fan is well aware. But this gap exists in most other areas of human endeavor as well. The very best academics, the best artists, or closer to home for me the very best software developers, play at a completely different level. Which is of course why I follow Sam Altman and Marc Andreessen on twitter. Top of their fields. The point in bringing this up is there’s a polite social fiction outside of sports that gaps in ability are to be downplayed. And this is great! Arguably all social progress in the past few hundred years has centered on equal rights and treatment for every human being. But this important ideal and social norm should not obscure the fact that human abilities in any particular vocation vary by orders of magnitude. Which is easier to demonstrate using quantitative data from a field like chess which uses the numerical ELO rating system. Magnus Carlsen of course being the stand out, with a 2876 ELO rating.
The Luke Muehlhauser chart below tracks the ELO ratings of computer chess programs across decades. I used it in one of my favorite posts “What Chess and Moore’s Law teach us about the progress of technology,” which we’ll leverage now. For this post I’ll just mention ELO is an exponential rating system where a 400 point gap in chess rating means 10x better, and the chart below shows an approximate doubling time of 2 1/4 years.

Since human ability runs roughly to a bell curve Paretian power law distribution, we can combine the computer ELO data above with human percentile to get the table below. Note how long it takes to get that last few percent.
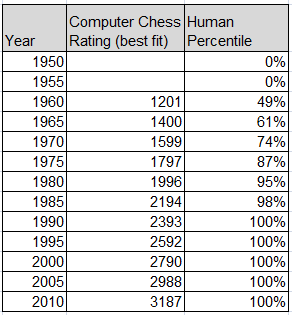
From my earlier computer chess post:
Given the upper limit on human chess ability has hovered around the 2800 rating mark for a long time, and the grinding linear improvement (on an exponential scale) in computer chess, you might expect predictions about when a computer would beat the best human were consistently boring. Not at all! Tech enthusiasts constantly overstated the case, as this at times comical history shows. The first prediction that “within 10 years a computer would be world chess champion” dates to 1957. “Within 10 years” is claimed again in 1959. The first chess program that played chess credibly dates to 1962. So another “10 years” bet was made in 1968, and yet another in 1978. By the 1980’s it became clear where things were headed, though the topic continued to be hotly debated right up until 1997 when Deep Blue defeated reigning world champion Garry Kasparov.
What I want to comment on is the incredible human ability gap we’re seeing here. A mid-level chess player has a 1200 rating. That means Magnus Carlsen is 2800-1200 = 1600 ELO points better. Since each 400 points is 10x, that means 10^4 = 10,000 times better. So from 1960 until 2000 chess computers got 10,000 times better, which sounds about right given Moore’s law coupled with improved algorithms. But even at that exponential pace, the gap between being an average chess player and the very best took four decades to cross. During which time researchers we’re constantly telling everyone “just 10 more years.” Furthermore, a complete beginner rating is only a few hundred ELO points, so there’s easily another 10×10 = 100x between beginner and mid-level. This means from top to bottom we’ve got a range of human ability of 1,000,000 times. Is LeBron James 1,000,000 times better at basketball than the worst human player, and 10,000 times better than an average recreational player? Obviously it’s not possible to say for sure. But I think it’s not an unreasonable position. Elite athletes really are just that good. Watch the NBA playoffs and then go outside and try to shoot a basket yourself. Trust me. LeBron really is 10,000x better than, well, me at least. Sports helps us calibrate our intuition as to how large the gap is in human ability really is.
What’s also fascinating to note here is the very best chess being played today is freestyle chess, where humans paired with computers play far better than either alone. And this makes intuitive sense. Manchine intelligence and human intelligence have completely different strengths and weaknesses, so the combination is greater than either alone. Of course eventually computers will get so good humans won’t incrementally improve their game, but we’re not quite there yet.
Now let’s pick a human skill which both humans and computers may capable of. For our arbitrary example let’s pick something I’ll call “Improving Artificial Intelligence” or IAI. What we want to understand is what happens to progress in IAI as machine intelligence gets better. At what point could IAI recursively self-improve? Once it gets to a typical human level, this means the very best humans will still be 10,000 times better than machines. So probably at that point IAI will still mostly be done by the very best humans. Then in another four decades the best machine will equal IAI for the best human. Granted, machines are better at some things than humans and worse than others. But this just leads us into thinking that “freestyle IAI” is the way to go, and that this combo will remain far better than either a pure human or pure machine IAI alone. And this will still be true for some period of time even after the machines match the single best human in IAI. Just like we’ve seen in computer chess. Although eventually of course computers will be so good even without pairing up with the best humans won’t help them.
So this is my soft takeoff argument. Human beings are not some uniform undifferentiated set of clones with a single common level of capability. As machines improve, they won’t march past humanity at a single moment in time, but rather have to cross a vast chasm of human ability before being smarter than the smartest humans. This will take decades even at the incredible exponential pace of Moore’s law.
How does Bostrom deal with the soft versus hard takeoff argument? He merely posits it. There’s no historical argument. No analogy to other tech history, like computer chess, or analysis of the range of human ability as in this post. In fact Robin Hanson debated this same point with his former co-blogger and hard takeoff advocate Eliezer Yudkowsky. Please note that Hanson and Yudkowsky call hard takeoff “foom”, which I find needlessly obscure. I guess it’s foom as in a nuclear explosion. Anyway, with this foom terminology in mind, let me quote from Hanson’s review of Bostrom’s book, in particular on the likelihood of hard takeoff:
Bostrom distinguishes takeoff durations that are fast (minutes, hours, or days), moderate (months or years), or slow (decades or centuries) and says “a fast or medium takeoff looks more likely.” As it now takes the world economy fifteen years to double, Bostrom sees one project becoming a “singleton” that rules all.
And why hard takeoff?:
Bostrom’s book has much thoughtful analysis of AI foom consequences and policy responses. But aside from mentioning a few factors that might increase or decrease foom chances, Bostrom simply doesn’t given an argument that we should expect foom. Instead, Bostrom just assumes that the reader thinks foom likely enough to be worth his detailed analysis.
And that’s what’s annoying about Bostrom’s influence on the AI Risk debate. It’s a fine book and a fascinating and important topic. But by sweeping the hard versus soft AI takeoff debate under the rug, many people reading his book aren’t even aware that it’s the central question for AI Risk. Instead people get caught up in psuedo-debates.
To finish, let me recap my talking points on ways to avoid the AI Risk pseudo-debate. And in this, I’ll mix in some earlier quotes from the excellent Slate Star Codex as noted.
- “First, we are nowhere near human-level intelligence right now, let alone superintelligence, and there’s no obvious path to get there from here.”
- “Second, if you start demanding bans on AI research then you are an idiot.”
- Both skeptics and believers agree the correct response to AI Risk is that “although we should probably get a couple of bright people to start working on preliminary aspects of the problem, we shouldn’t panic or start trying to ban AI research.”
- Median consensus for human level intelligence is roughly 2050. Not tomorrow, but people alive today may live to see it. Also note my personal opinion is it’ll be just like computer chess, the researchers are awesome but optimistic.
- Avoid psuedo-debates and strawman claims. No one is saying we have a clear path to human level intelligence right now. No one is saying we should ban AI research. No one is saying human level machine intelligence is closer than decades away. No one is saying AI Risk isn’t a real thing we should take seriously. Note: “No one” here means people who understand technology and have at least have followed the basic Bostrom arguments.
- The central debate in AI Risk should really be about hard versus soft takeoff, but this argument gets ignored for pseudo-debates.
- For what it’s worth, my core soft takeoff argument above is built on the at least 10,000 times gap in human ability, plus an analogy to computer chess. So even at exponential growth, it’ll take machine intelligence decades to slowly cross the chasm of human abilities. During which time we’ll have an exciting but reasonable window of opportunity to sort things out.
- Samantha would have completely freaked me out. Theodore has issues.
- Captain Kirk’s ability to shut down a rogue AI using a simple logic contradiction as demonstrated in The Ultimate Computer episode is not a generalizable AI Risk solution. That trick only works for Kirk.
Finally, I want to say Natural Language Processing (NLP), as seen in Star Trek and currently existing on your phone and watch as Apple Siri or Google Now, continues to be an incredibly exciting and disruptive technology. The Star Trek computer is amazing. For example there’s no reason Apple and Google can’t shortly come out with a Magic-style text service for people to get their Siri answers via text messaging instead of more intrusive (in public) voice commands. Never bet against text. The flipside of the growth of NLP is as people talk and text to their phones and watches more and more, they’ll anthropomorphize their Star Trek computers more and more. Which means the AI Risk debate has unfortunately just gotten started.
____________________________________________________________________
APPENDIX
My blog posts on related topics:
- “What Chess and Moore’s Law teach us about the progress of technology” link
- “Apple’s strategy tax on services versus Google. Voice interaction becoming the ‘God particle’ of mobile.” link
- “The God Particle Revisited: Augmented Audio Reality in the Age of Wearables.” link
Additional writing:
- Robin Hanson on AI progress, Her, Bostrom and FOOM
- Scott Alexander of Slate Star Codex AI Researchers on AI Risk. Really great blog with eclectic longform analysis. By the way “Scott Alexander” is a pen name as well as an anagram for the blog name. UPDATE May 30: Scott has a new follow on post No Time Like the Present for AI Safety Work, which links back to this post, where he quotes me about hard versus soft as a key aspect of the debate. As usual, lengthy, detailed and interesting. Completely agree with his thesis that hard takeoff is a real possibility and so we should continue working on AI Risk. It remains to my mind the only serious existential threat to humanity coming. Which I should have made more clear in my original post above. This is true despite my being (for now) on the soft side.
- Sam Altman’s posts on Machine Intelligence Part 1, Part 2
- Nick Bostrom home page
- Machine Intelligence Research Institute (MIRI) web site, where Luke Muehlhauser and Eliezer Yudkowsky reside. They were mentioned above.
Finally, despite my complaints above about the movie Her, I want to say I was completely serious about it being a great movie. It has a great and unique vision and stays true to itself. Sure I cringed at the economics of AI. But the vision of a world where we talk to computers in earbuds rang completely true. In particular the street scenes where everyone is caught up in talking to their phone/earbuds/computers somewhat oblivious to their surroundings. That feels exactly like the future. The story and acting were great. A common mistake of science fiction is to assume everyone will be thrilled with the new tech. Louis CK is right: everything’s amazing and nobody’s happy. That’s just human nature. And Her captured talking AIs as commonplace and boring, which feels exactly right, and something most SF gets wrong.

Loved this post. I’m going to send this link to both Erin and Claire, I think they will enjoy it.
I agree the very light argumentation in favor of hard takeoff is a weakness of Bostrom’s book. Have you read Yudkowsky’s “Intelligence explosion microeconomics?” That’s a fuller treatment, though still not a convincing argument.
Thanks for reading and commenting! Hope you found nothing glaringly wrong in the post. Was planning on looking into the Hanson/Yudkowsky’s blog series/ebook first. Let me look at “Intelligence explosion microeconomics” instead and see if that would be better. Thanks for rec. Not sure I would be convinced, but really want to read and understand the strongest case for hard takeoff, so if that is Yudkowsky then will take a look.
I think your cautionary attitude toward a hard takeoff is well supported and logical, but I think that one programming aspect that you may have to take into account:
One of my closest friends, a biomedical engineer and programmer, has pointed out that systems emergence (a concept seen in atomic construction, the emergence of life, consciousness, and also in programming) is the key aspect of AI. In the case of AI, the takeoff is fundamentally different from other technological developments because it will likely be not because of a human’s direct programming development, but because a human creates a program that can create a program that has AI.
Because systems emergent are by nature quantum leaps, and because it will likely be an indirect achievement completed by a computer, to observing humans there is a good chance AI’s emergence will at least seem to be nearly immediate, and may BE immediate, since we do not fully understand the quantum leap of systems emergence. I recognize your counterarguments, and I just think this introduces yet more uncertainty to this discussion.
Interesting and illuminating take on what the real debate is!
It seems to me your argument for a soft transition depends on the assumption that we’re not already in a supercritical phase. What I mean by this is that, in terms of raw hardware technology, perhaps we could already build machines that are trillions of times better thinkers than the best of us today, if we only knew *what* to build, and what software to run. (Electronics vs chemistry gives a factor of a million in speed, many gigabytes of fast working memory helps, we could put logic on the memory chips to get another big factor, etc.) This means that it might just take one great idea to span an enormous gulf.
Hi,
Your discussion about the gap in abilities you talk about is based on a misconception. A rating system like ELO points or (IQ score) for that matter doesn’t measure abilities directly, it measures the frequency (or rarity) of players relative to a given population. So for instance, an elite chess player scored with a 10 000x gap over an average player doesn’t mean the elite player is 10,000x as good, it just means that a player at that level of ability is 10,000x as rare in the population.
Actual absolute difference in cognitive abilities between humans is very small. We know this from the Pareto principle- for example only 20% of the effort gives you 80% of the result. It implies that big gains come from very small differences. Bostrom has discussed this point with his chart where the ‘Village Idiot’ and ‘Einstein’ are shown to be close in absolute cognitive abilities, and so the super-intelligence can actually shoot right past them very quickly.
ELO is a measure of competitive win, which is why it’s also used in sports for example by Nate Silver for basketball. My other post on Chess and Moore’s law covers this in more detail, let me quote from that:
Chess player’s competitive level is ranked using the ELO rating system. Players gain rating points by beating a competitor. And lose points when beaten. The scale is constructed so that “for each 400 rating points of advantage over the opponent, the chance of winning is magnified ten times in comparison to the opponent’s chance of winning.” The competition outcome is modeled as a logistics curve. The way the math works, when a player rated 1100 competes against a player rated 1000 (rating gap of 100), they’ll win 64% of the time. When a player rated 1400 player competes against a player rated 1000 (rating gap 400), they’ll win 92% of the time. What matters here is: a) the chess rating scale is exponential, and b) a 400 point gap means 10x better.
My point here is that cognitive abilities may be close (I actually don’t believe this) but the argument doesn’t hang on this point. Rather it only assumes that through practice and effort plus cognitive differences that competitive outcomes along any particular skill set are massive. Which ELO supports for Chess. And I am asserting for competitive sports as well. And by analogy also AI innovation.
All that said, this is an interesting objection. So let me do my homework on that aspect and re-look at Bostrom’s section there on that point. But I think it’s not logically impossible that cognitive differences aren’t massive but ability differences along any particular skill are massive.
Finally, I don’t think hard take off is impossible. Just arguing it’s less likely than is typically made out. Or at least that’s my (current) position. Thanks for engaging.
Yes, I know the ELO scale is exponential. IQ scale is also exponential, so I suppose they’re roughly analogous.
The point is that these scales are not measuring absolute cognitive abilities, just relative outcomes. So for example, to say that a 400 ELO point gap means ’10x as good’ is very misleading.
You can clearly see its misleading by considering your example of LeBron being ’10 000x better than you’ at basketball. In fact, the actual differences in physical attributes (speed, coordination, etc.) between you and LeBron are quite small – Lebron isn’t zipping around like ‘The Flash’ superhero at 10,000 miles per hour! A scientist watching the two of you play would only measure marginal speed differences between you and LeBron.
See ‘Super-Intelligence’, (Bostrom), Chapter 4, ‘The kinetics of an intelligence explosion’.
Thanks for making this clear as I think I understand Chapter 4 argument better. Let me restate your point. ELO measures competitive outcome gaps. So in that (assuming no crazy tail distributions which of course we’ll just assume for now even though not true) this would mean LeBron beats me 10,000 times to 1. And this is correct! But if I could improve my speed by just say 5%, this would change the competitive ELO outcomes massively, and that 5% change could lead to a 100x shift in my ELO rating and I’d just lose 100 to 1, and maybe another 5% would let me win. Competitive ELO outcomes can be driven radically by small changes in the underlying innate talent/skill/etc.
Now. Let’s try to apply this as an empirical claim about the way the world works. In particular, let’s apply this claim to how computer chess developed. If this were true, we’d expect computer chess to improve it’s ELO rating faster than a steady Moore’s law tempo that history shows. Or to use our analogy, maybe getting 5% faster reflexes is actually exponentially hard of a hill to climb.
My point here is that this is not a proof but a fascinating conjecture about the way it will work out. But the argument against is to use the history of other computer weak and narrow AI like computer chess as a guide. So i’m not convinced, but learning a lot and certainly a reasonable conjecture. Will re-read that and think about it more.
Nathan, if you use go as an example instead of chess, you’ll find the range of skill to be at least twice as large. With go, one gets the 10x as good with two stones difference in strength, like a 1kyu vs. a 3kyu. With a range from 30kyu to 9p (basically 13dan), you have about 21 levels of 10x improvement, so a top professional go player like Lee Sedol would be 10^21 better than a beginner, and 10,000,000 better than me at 2kyu. That means LeBron would be not 10,000 times better but 10,000,000 times better than an average competitive b-ball player. For more info about go ranks, see : http://en.wikipedia.org/wiki/Go_ranks_and_ratings
Another point I’d add is that Moore’s law may prove to be an anomaly in the last 50 years. Although history is littered with naysayers of Moore’s law, but exponential growth may actually become exponentially difficult. For example CPU frequency stopped scaling higher more than 10 years ago. Now we are just jamming in more cores. But our ability to program parallelly is improving quite slowly.
If time lapses between each doubling in Moore gets dragged out, from every 2 years to 3 then 4 etc, it may well be 2100 or beyond before we meet Samantha.
Your problems with the economics of Her seem flawed.
For starters, it was written before 2013, when discussion of AI risks was not a mainstream headline grabber. It would not be unreasonable to extrapolate a largely uninterested consumer population on the near future of our recent past. It is still a niche concern, and probably ninety percent of the people in Theodore’s demographic I have spoken to about the topic have never heard of AI, or the concerns of Hawking et al. Why would Theodore even know if there was a big existential risk debate happening? His character was disengaged from society.
Secondly the hard takeoff happens during the movie. Explicitly. We see Samantha gain abilities every scene. Theodore didn’t buy a human level or greater intelligence for a pittance, he bought a near future siri analogue which could do things not unlike Google mail/now can now, and it bootstrapped itself into super intelligence.
I personally find the world of Her highly plausible. Even ignoring pithy statements re: star trek, the only real criticism of Her I can see is that it is a hard takeoff.
You don’t need to know about AI Risk to know that Her is unrealistic, just basic economics. Think about it: Why is Theodore paid to do his job? His company could hire an AI to do it, for a fraction of the cost, hundreds of times faster. There would also probably be huge technological developments happening very quickly as the AIs worked on them, etc.
Every company didn’t have their best and brightest prioritize writing the best chess programs. Big Blue was the only major project and in general it’s not something that pays dividends. AI has the best and brightest working on it, and it does pay big dividends.
Some not particularly novel objections that still seem to have bite against OP:
1 the sequence of better and better chess engines were made by humans. Humans “waste time” on eating, defacating, sleeping, socializing and many other things. A human level AI may not waste any time.
2 once a human level AI is achieved it will likely be radically less costly to generate copies of it compared to the cost that went into the first instance. Multiple incentives can make humans engage in a quantitative race.
Now combine 1 and 2 and imagine a cluster of 10.000 AI beings of at least average engineer intelligence worked in concert 24/7.
3 add to that the further Bostrom point that each incremental AI discovery made by such a cluster can likely quickly be put to use to enhance the AI of the cluster itself.
4 it is a very long time between now and 2050. It is easy to fall into the thought experiment of imagining takeoff times for human level AI:s in a world pretty much like the current. But the external infrastructure and resources for such human level AI to make use of in 2050 will likely be very different from the current.