
With Apple’s announcements at WWDC and Google’s announcements at Google I/O, there’s a reasonable case to be made that 2015 will be looked back on as the year we transitioned from the mobile tech era into the machine learning era. To be clear, that’s a huge oversimplification. Smartphone mobile tech is still changing rapidly (watch versus phone) and machine learning is itself tightly coupled to mobile’s rise. And there’s plenty of other technology vying for a similar claim: solar, genomics (CRISPR), Internet of Things, Bitcoin, 3D printing, other big data and cloud, etc. And yet. The world is so complex. Honing in on a single simplifying theme can provide insight. So let’s run with this one to see where it leads.
Start with this Horace Dediu chart from last year showing US smartphone penetration over time.
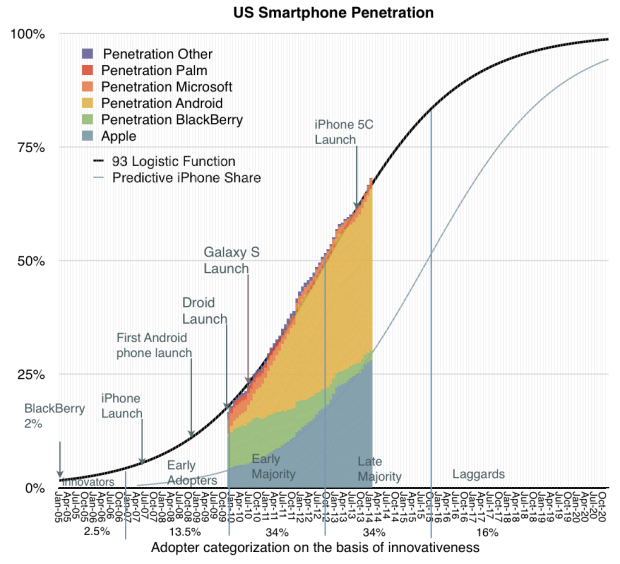
For adoption profiles like this, what we see time and again is it’s during the early rapid growth phase that technology is in highest flux, and it’s by the Early Majority phase that the winners and losers are unambiguously sorted out. Looking at the curve above, it’s not surprising the iPhone came out in 2007, or that the Android explosion didn’t start really happening until 2010. But by now things have stabilized, at least as far as smartphone ecosystems. Though to be clear, what’s getting built on top of those ecosystems is still shifting.
The chart above shows if we want to forecast which technology will be the largest driver of change in the next 5-10 years, mobile is boring. Or to be more exact, the benefits of mobile smartphones yet to be claimed are massive, especially for the poorest people in the world. But the way those benefits will come to fruition is fairly predictable. In the jargon, sustaining and efficiency innovations. To find new big changes in tech winners/losers, we need to look for something that has traction now and is rapidly improving, has quickly expanding adoption, and has the largest disruptive potential to existing businesses. For several years I’ve argued what best fits the bill is Machine Learning, and in particular Natural Language Processing (talking computers). Case in point – earlier this year Uber devastated Carnegie Mellon’s robotics and machine learning department by hiring away 40 of its top researchers and scientists. And Facebook is greatly expanding it’s AI reach. The field is deservedly white hot. And while both Apple and Google have had voice interaction on their platforms for years, it’s only this year in 2015 that both companies made machine learning and NLP the clear centerpiece of their annual showcase events.
Privacy and Ads in the Machine Learning era
But Apple and Google have very different reputations on privacy. As a marketing push just ahead of Apple’s WWDC event, Tim Cook lashed out at Google (not by name) with this quote: “We believe the customer should be in control of their own information. You might like these so-called free services, but we don’t think they’re worth having your email, your search history and now even your family photos data mined and sold off for god knows what advertising purpose. And we think some day, customers will see this for what it is.” This kicked off quite a twitter tech debate, much of it centered on Ben Thompson’s excellent post (subscription $10 USD per month but well worth it), pointing out how misleading Cook’s characterization was. A view I share by the way.
One point of confusion was how Facebook and Google actually make money with ads. The right analogy here is print magazines. If you subscribe to a print magazine about cars, the car companies can pay to target you with ads. But….the advertisers themselves never learn anything about you directly, they just get to place ads in front of people who like cars. Your personal data (your address, etc) continues to be held privately by the magazine. Facebook and Google advertising works just that way. Advertisers pay to put their ads in front of you, and you may click on them, but the advertisers themselves don’t get your personal information.
But if this works just like print ads back in the day, why are people so upset? One could argue that online is different since ad networks are much looser with your data than Facebook and Google proper. An important and very true point. But I think the fundamental, underlying reason people are upset is machine learning can be very very creepy. Simple as that. It’s not really about ads or business models for selling ads. People complained about ads in magazines, complained about ads on radio, complained about ads on TV, and are now (surprise!) complaining about ads on the web. Ads have always been annoying. The real irony here is the people who complain the most about seeing too many ads that aren’t relevant to them also complain about the solution to their own problem: far fewer but more targeted ads based on precise machine learning. Oh well. The new thing about the way ads behave online is they act like salt in the open wound caused by creepy machine learning.
The case that comes to mind is from a few years back when Target figured out a teenage girl was pregnant before her father did. The teenager changed her old behavior by purchasing scent-free soap, extra-big bags of cotton balls, hand sanitizers and washcloths. What you buy is data every retailer already collects with loyalty programs. So using some basic machine learning, Target sent her coupons for baby clothes and cribs. And her Dad freaked out and complained to Target, only to later discover she was in fact really pregnant. Fortunately Target went out of business once this was discovered, and every company in the world stopped using machine learning against their loyalty program data, and all was well. Strike that. What happened was people freaked out for a day or two, and then Target created even more sophisticated advertising which masked their pregnancy understanding by mixing in unrelated ads, and everyone moved on without a second thought. Note how even though print(!) ads were the trigger, what was truly creepy was Target knowing a teenager was pregnant before her Dad did.
One could still defend Cook’s privacy stance by saying Apple parsimoniously collects only the data it needs to deliver the customer features at hand. Which is true enough since their business model is selling devices, not ads. And then contrast them with Google, who wants to understand everyone more broadly to not only create better cloud products like the new and amazing Google Photos (good), but also to target people with fewer and better ads (apparently very bad). Hence Google’s machine learning is more creepily ambitious and their motives suspect. But I think this Apple argument breaks down in two ways. First, as long as security is good, where Google is clearly better than Apple, I fail to see a huge distinction between data locally stored on your wrist versus in the cloud. Especially if both have machine learning applied to it anyway. Second, for Apple, today’s unneeded information may become tomorrow’s needed information. And by painting themselves in a corner on privacy Apple is setting themselves up for either machine learning failure or hypocrisy down the road. If Apple is to continue to make the very best products, they need to understand their users with machine learning better every year. And this means more data every year.
Let’s use activity circles on Apple Watch to make this more clear.

Right now this is a cool but relatively unsophisticated feature. But project this forward five years. Or more generally project Apple Watch health tracking forward five more years. Suppose I have high blood pressure or disabilities. What if I’ve had heart surgery (this is true for me). How much should I move, exercise, stand? With a supercomputer watch on my wrist that tracks my heartbeat, and an Apple ecosystem that knows all my health information, I expect the app on my watch to take all my health data into account or it’s not really a premium product. And Apple sells premium products. This means knowing how much I sleep, what my meds are, what my health issues are. In five years premium health products need to do more than remind me with cool tracking fitness circles. Sure, Apple can say they won’t use the health data they collect to sell ads. But as I said earlier, selling ads has a long history of being merely annoying. It’s not a mortal sin in and of itself. And health with Apple Watch is but one example. In the machine learning era, supercomputers will know nearly everything about you. Whether on your wrist or in the cloud. And while this seems creepy now in 2015, it doesn’t mean the machine learning negatives will on balance outway the positives. It’s quite easy to imagine a future where people take it for granted that supercomputers know where they are and what they’re doing at all times. Even if those of my generation get tempted to yell at those kids to get off my lawn.
Apple’s prospects in the Machine Learning era
It’s pretty easy to see how Apple’s current privacy positioning could go wrong. Here’s one hypothetical example. Apple haters point out poor people tend to rely on ad supported free services. And note that Apple says free services are very very bad, and companies like Google invade your privacy. To quote Tim Cook again, these companies have your “data mined and sold off for god knows what advertising purpose. And we think some day, customers will see this for what it is.” And now you’ve proved it: Apple hates poor people, and thinks privacy is only for the rich. I don’t see any way around admitting that Apple’s overly strident position on privacy is a blunder. Outside of tech circles, people have shown time and again they value convenience over privacy. Even worse, there’s a risk that inside the company Apple could cripple their machine learning efforts by overcommitting to their own marketing and privacy ideology. I noticed Apple’s Phil Schiller was on message last night about privacy on John Gruber’s The Talk Show. It’s hard to be certain of Apple’s motivation here. It’s likely some mix of being overly creeped out by machine learning, putting their relative backwardness in cloud and machine learning in the best light, having some real and serious moral concerns about privacy, plus some cynical distancing from Google. The latter since they know Google will be the one to bear the brunt of the lawsuits and tech regulations around privacy as machine learning explodes. And then Apple can follow serenely behind in their wake.
With that said, Apple is one of the greatest companies in the world with massive strengths. So I’m already on record saying despite machine learning being a big threat to Apple, in the end they’ll do fine. One angle I want to emphasize in this post is that the smaller computers get, the more Apple’s design strengths on personalized computing come into play. They did better with phones than laptops, and will do better on watches than phones. It’s important to remember that even though computers in the cloud have unbelievable capacity, the one in your pocket or on your wrist is also a supercomputer. Moore’s law applies to both ends. Moreover, being the default on iOS is a huge advantage. Apple maps continues to lag several years behind Google maps, but it gets 3.5 times the usage. That’s why back in 2012 I wrote a post “The Apple maps kerfuffle means the opposite of what most of the press is saying“. Decent but not best is workable as long as you don’t get too far behind, and you’re behind in an area that’s not your primary differentiator. This can be true even for something as important as machine learning and natural language processing, despite what some overenthusiastic tech aficionados may believe. What I noticed and liked about the Apple keynote at WWDC this week is Craig Federighi clearly loved all the new cool features based on machine learning and searching with natural language. He has an infectious enthusiasm. It’s great to see. Apple clearly takes machine learning very seriously. They just want to do it their own quirky and backhanded way.
One of the best pieces of management advice I ever got was to focus less on fixing my weaknesses (though they’re important to work on). Instead I should double down on my strengths, leveraging them to compensate for everything else. To use a basketball analogy, if you are a great 3 point shooter, then become the very best 3 point shooter ever to play the game. This opens up everything else. That’s just as true for companies as for individuals. Play to your strengths. The best outcome for fans of Apple and Google is that Apple continues to focus on designing the best pocket and wearable supercomputers, while doing fine but not spectacularly well at machine learning. While Google creates the best machine learning engine the world has ever seen, but struggles somewhat with their weakness for shipping demoware instead of completely finished hardware products. And both of them succeed in pushing the other forward in their weak spots.
__________________________________________
APPENDIX FOR MORE READING
My related posts:
- My post last week on the rise of NLP. Similar theme to this post but a focus on how Google can rise again: Talking computers pose a threat to current Apple versus Google market segmentation. Beyond Peak Google.
- My larger argument on privacy. Why we’re headed for a loss of privacy and moving towards the surveillance society.
- Supercomputers on both clients and servers. Don’t say thin client ever again.
- My original 2013 post on why cloud services are a threat to Apple by Google.
Other writers on the same topic, mentioned or discussed above.
- Ben Thompson (subscription required) clarifying privacy and security. Great post.

- John Gruber comments on an older 2014 piece by Dustin Curtis making the same case as me above.

- UPDATE – shortly after I published this post, via Chris Dixon on twitter I saw this excellent Farhad Manjoo piece from the New York Times “What Apple’s Tim Cook Overlooked in His Defense of Privacy“
Finally some pro and con privacy tweets I saw last week after Tim Cook’s statement. Gives you a flavor for what people are saying. (Everyone below is a good follow by the way).

“The right analogy here is print magazines. If you subscribe to a print magazine about cars, the car companies can pay to target you with ads. But….the advertisers themselves never learn anything about you directly, they just get to place ads in front of people who like cars. Your personal data (your address, etc) continues to be held privately by the magazine.”
Many a print magazine I’ve subscribed to comes replete with little vendor “reader survey” questionnaire cards slotted between the pages or loosely attached to the sleeve or binding, asking for precise personal information in return for a chance to win a holiday, pottery prize or discount. So it’s not for want of trying to get this info, and surely the magazines would not be allowing this unless some financial incentive was involved.
Very nice piece. I thought your comparison to a print magazine was an apt illustration of how Google and Facebook don’t sell your data directly. However, it also illustrates why many people find Google and Facebook’s practices highly immoral. I willingly and explicitly send a magazine my address knowing that the magazine I receive will contain ads related to the topic of the magazine. Contrast this with Google and Facebook: in addition to the information I willingly and explicitly give them, they surreptitiously track my activity around the web without my knowledge or permission using technologies such as Like buttons or Google Analytics.
Many of the defenders of Google and Facebook I’ve seen around the web in these last few weeks seem to be of the opinion that there can’t possibly be anything morally wrong with the data gathering practices of these companies so long as they only use the data for anonymous ad targeting. But this is clearly wrong; would it be OK for Google to secretly install video cameras in people’s homes, so long as the gathered data was only used for algorithmic ad targeting? I have a feeling most people would object if they found a Google camera hidden in their bedroom.
So while Tim Cook was mildly misleading with his vague “sold off for god knows what advertising purpose” comment, his larger point is absolutely valid.
“The real irony here is the people who complain the most about seeing too many ads that aren’t relevant to them also complain about the solution to their own problem: far fewer but more targeted ads based on precise machine learning”
This is such an idiosyncratically shitty line of reasoning — ie no two people could be so dumb as to independently follow the reasoning — that I now conclude with 100% probability that you are startup L jackson
If I were to write that again with more nuance, I’d say that one of the main complaints of the current web is so many ads that are so aggressive. Pop ups, video that plays before you can see the site, etc. And those ads are often for things I don’t even care about and would never buy, so they’re a waste. The potential solution to this problem is using machine learning to target ads more closely to what people want, which could lead to far fewer ads. But at a cost of privacy. But people who are concerned about privacy are often (though not always, and you may be an exception) people who hate too many ads. So there is some irony in this. Of course if you hate that corporations have and use all your data this will piss you off, regardless of whether or not it leads to fewer ads.
Anyway, I don’t recall Start L Jackson ever making this argument. But fair enough it’s something he could say, or perhaps if he said it I missed it. Sorry to say that I’m not him though.